

How Seq2Seq Transformers Work A Practical Perspective
- May 2
- 7 min read
Sequence-to-Sequence (Seq2Seq) Transformers sit at the center of modern natural language processing, quietly running everything from machine translation and summarization to conversational systems and code generation. Their strength comes from a combination of self-attention and parallel computation, allowing them to model long-range dependencies and contextual relationships far more effectively than earlier architectures like RNNs and LSTMs. As sequence modeling tasks grow in complexity and scale, these models have shifted from being a research breakthrough to a practical necessity for building reliable, high-performance AI systems.
This blog takes a structured, practical approach to understanding how Seq2Seq Transformers actually work beyond surface-level intuition. It traces the architectural evolution from recurrent models and early encoder–decoder frameworks to attention mechanisms and fully attention-based Transformers, while connecting these ideas to the complete encoder–decoder pipeline. By the end, the focus is not limited to conceptual understanding, but extends to developing the clarity required to implement, analyze, and optimize Seq2Seq Transformer models effectively.

What are Seq2Seq Transformers?
Sequence-to-Sequence (Seq2Seq) Transformers are deep learning models designed to map one sequence into another, while keeping context intact across the entire transformation process. In plain terms, they take an input sequence like a sentence, code snippet, or time series and generate a corresponding output sequence that could be a translation, summary, or structured response. Unlike older approaches built on recurrent architectures, Seq2Seq Transformers process the entire input at once, which allows them to capture long-range dependencies and complex relationships without the bottlenecks of sequential computation.
At the core of a Seq2Seq Transformer lies the encoder-decoder architecture. The encoder reads and converts the input sequence into a rich, contextual representation, while the decoder uses this representation to generate the output sequence step by step. What makes this architecture powerful is the attention mechanism, which enables the model to focus on relevant parts of the input during generation instead of relying on a fixed internal state. This dynamic context handling is what allows Transformers to outperform traditional models in tasks that require nuanced understanding.
Another defining aspect is the removal of recurrence entirely. Instead of processing tokens one at a time, Transformers rely on self-attention to understand relationships between all tokens simultaneously. This not only improves performance but also makes training highly parallelizable, which is why these models scale so effectively. Combined with positional encoding to retain sequence order, Seq2Seq Transformers strike a balance between structure and flexibility, making them the foundation for many state-of-the-art systems in natural language processing and beyond.
The Evolution Toward Seq2Seq Transformers
Seq2Seq Transformers didn’t just appear because someone had a sudden flash of brilliance. They’re the result of years of incremental fixes to models that kept running into the same wall: handling sequences is hard, and doing it efficiently is even harder.
The story begins with Recurrent Neural Networks (RNNs), which were the default choice for sequence modeling tasks like language modeling and speech recognition. Early systems such as Google Neural Machine Translation (GNMT) relied heavily on stacked RNNs. These models processed tokens one at a time, carrying context through a hidden state. While conceptually sound, they struggled with long-range dependencies due to vanishing and exploding gradients, making it difficult to retain information across longer sequences.
To address this, architectures like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs) introduced gating mechanisms that allowed models to selectively retain or forget information. This significantly improved performance in tasks like machine translation and speech processing. Models such as Sequence to Sequence Learning with Neural Networks demonstrated how encoder-decoder setups using LSTMs could map entire input sequences to outputs. Still, these models relied on compressing the entire input into a fixed-length vector, which became a bottleneck as sequence length increased.
The next major breakthrough came with attention mechanisms. Instead of forcing all information into a single vector, attention allowed the decoder to dynamically focus on different parts of the input sequence during generation. This idea was formalized in works like Neural Machine Translation by Jointly Learning to Align and Translate, often referred to as Bahdanau Attention. Later, Effective Approaches to Attention-based Neural Machine Translation introduced refinements that improved alignment and efficiency.
These models significantly boosted translation quality and became standard in production systems, including later iterations of GNMT.
The turning point came with the introduction of the Transformer architecture in Attention Is All You Need. Transformers removed recurrence entirely and relied solely on self-attention mechanisms to model relationships between tokens. This allowed full parallelization during training and made it far easier to capture long-range dependencies.
The encoder-decoder structure was retained, but both components were now built using stacked attention and feedforward layers.
This shift enabled a new generation of models. BERT leveraged the encoder side for deep contextual understanding, while GPT focused on decoder-style generation.
For full Seq2Seq tasks, models like T5 and BART demonstrated how Transformer-based encoder-decoder architectures could unify multiple NLP tasks under a single framework.
So the evolution is less about a single breakthrough and more about gradually removing constraints. First, memory issues were addressed with gating. Then representation bottlenecks were solved with attention. Finally, the inefficiencies of recurrence were eliminated altogether. The Seq2Seq Transformer is what you get when all those lessons are combined into one architecture that actually scales.
How Seq2Seq Transformer Mechanism Works
Sequence-to-Sequence Transformers operate through a structured encoder–decoder pipeline designed to model the conditional probability of an output sequence given an input sequence. Formally, for an input sequence X=(x1,x2,...,xn) and an output sequence Y=(y1,y2...,ym), the objective is to learn:

This formulation enables the model to generate each token conditioned on both the input and all previously generated tokens. Unlike earlier sequence models that compressed the entire input into a fixed-length vector, Seq2Seq Transformers maintain rich, distributed representations across all tokens, allowing them to scale effectively to longer and more complex sequences.
The process begins with input representation. Each token in the input sequence is converted into a dense embedding and combined with positional encoding to preserve order information. Since Transformers lack any inherent notion of sequence structure, positional encoding becomes essential in injecting information about token positions.
The encoder is responsible for transforming the input sequence into a contextual representation. It consists of multiple stacked layers, each composed of multi-head self-attention followed by a position-wise feedforward network. Through self-attention, every token interacts with every other token in the sequence, allowing the model to capture both local and global dependencies. The mathematical formulation of self-attention is given by:

Here, queries, keys, and values are linear projections of the input embeddings. While this equation captures the computational core of the mechanism, a detailed breakdown of its intuition, variants such as scaled dot-product attention, and the role of multi-head attention has already been covered extensively in the earlier blog : "The Attention Mechanism: Foundations, Evolution, and Transformer Architecture". In the context of Seq2Seq Transformers, this mechanism enables the encoder to produce a sequence of contextual embeddings H=Encoder(X), where each representation encodes information about the entire input sequence.
The decoder builds upon this representation to generate the output sequence. Structurally, each decoder layer consists of masked self-attention, encoder–decoder attention, and a feedforward network. Masked self-attention ensures that the model generates tokens autoregressively by restricting access to future positions. This enforces the constraint that predictions at time step t depend only on previously generated tokens y < t, preserving the causal structure required for sequence generation.
The second attention block within the decoder, known as encoder–decoder attention, allows the model to align output tokens with relevant parts of the input sequence. In this step, queries are derived from the decoder states, while keys and values come from the encoder output H. This interaction enables the model to dynamically focus on different regions of the input during generation, a critical capability for tasks such as translation and summarization.
Following the attention layers, each block includes a position-wise feedforward network defined as:

These transformations are applied independently to each position and are combined with residual connections and layer normalization to stabilize training and improve convergence. This design ensures that the model not only captures relationships between tokens but also refines individual token representations.
At the final stage, the decoder produces logits that are transformed into probabilities using a softmax function:

The model is trained using a cross-entropy loss function, which measures the discrepancy between predicted and actual sequences:
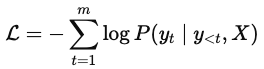
During training, the model is not left to figure things out on its own step by step. In contrast, during inference, the model generates tokens sequentially, using its own previous predictions as input. This distinction is crucial, as it introduces challenges such as error accumulation during generation.
In essence, the Seq2Seq Transformer integrates self-attention, encoder–decoder interaction, and feedforward processing into a unified architecture that overcomes the limitations of earlier sequence models. While attention serves as the foundational mechanism enabling contextual understanding, the surrounding architectural components ensure that this capability is scalable, stable, and effective in real-world applications.
Putting It All Together: Theory to Practical Clarity
At this point, the individual components of a Seq2Seq Transformer stop looking like isolated concepts and start behaving like a coordinated system. The input sequence is first embedded and enriched with positional information, allowing the model to retain order without relying on recurrence. This representation is then passed through the encoder, where stacked self-attention layers transform it into a contextualized sequence of embeddings. Each token representation now carries information about the entire input, not just its immediate neighbors.
The decoder takes over with a slightly stricter rulebook. It begins with masked self-attention, ensuring that predictions remain autoregressive and grounded in previously generated tokens. This is followed by encoder–decoder attention, where the model aligns its current generation step with the most relevant parts of the encoded input. Instead of blindly producing tokens, the decoder continuously references the input context, refining its predictions at each step. The final transformation into probabilities allows the model to select the most likely next token, gradually constructing the output sequence.
What emerges from this pipeline is not just a sequence generator, but a system capable of learning structured transformations between sequences. Every component contributes to this goal: attention handles relationships, feedforward layers refine representations, and residual connections maintain stability during training. When combined, these mechanisms allow the model to scale across tasks such as translation, summarization, and text generation without requiring task-specific architectural changes.
The real takeaway here is not just understanding how each block works in isolation, but recognizing how they interact during training and inference. Implementation becomes significantly clearer when this flow is internalized. Optimization choices such as layer depth, number of attention heads, or embedding dimensions start to feel less arbitrary and more like deliberate design decisions. At that point, the model stops being a collection of equations and starts becoming something you can actually build, debug, and improve without staring at it like it personally offended you.
Conclusion
Seq2Seq Transformers bring together years of progress in sequence modeling into a single, scalable architecture that effectively captures context, handles long-range dependencies, and enables efficient parallel computation. By combining encoder representations, autoregressive decoding, and attention-driven alignment, they overcome the core limitations of earlier approaches.
The real value lies in understanding how these components interact as a system. Once that clarity is achieved, implementing and optimizing these models becomes a structured process rather than trial and error. Seq2Seq Transformers are not just a powerful concept, but a practical foundation for building modern AI systems.



