

Deep Learning with Transformers in Python
- Dec 9, 2025
- 7 min read
Transformers have revolutionized the landscape of artificial intelligence, powering breakthroughs in natural language processing, computer vision, and beyond. Originally designed for sequence modeling tasks in NLP, these models have demonstrated remarkable versatility across a range of research domains. Python, with its rich ecosystem of AI libraries, provides researchers with the tools to experiment, implement, and extend transformer architectures efficiently.
In this blog, we will explore hands-on techniques for leveraging transformers in Python, focusing on practical implementation, model customization, and insights for academic and scientific research. Whether you are conducting experiments in NLP, designing novel architectures, or analyzing large datasets, this guide aims to bridge theoretical concepts with practical applications.

Why Transformers Are Essential in Machine Learning
Transformers have become the backbone of modern machine learning, powering state-of-the-art models across text, computer vision, audio, video, and multimodal tasks. They standardize model definitions so that a model built with Transformers can seamlessly work across training frameworks (e.g., PyTorch Lightning, DeepSpeed, FSDP), inference engines (vLLM, TGI), and complementary libraries (llama.cpp, mlx). This interoperability makes Transformers a central hub in the machine learning ecosystem.
Introduced in the 2017 paper “Attention Is All You Need” by Vaswani et al., Transformers are particularly effective in natural language processing (NLP) and increasingly in computer vision. The architecture relies on self-attention, allowing models to process entire sequences in parallel, unlike traditional sequential models such as RNNs and LSTMs.
Limitations of Traditional Sequential Models
Recurrent Neural Networks (RNNs) are a class of neural networks designed to process sequential data by maintaining a hidden state that carries information from previous steps. While useful for modeling sequences, RNNs process inputs one token at a time, which can lead to difficulty capturing long-range dependencies. This limitation is often exacerbated by the vanishing gradient problem, where gradients used in training diminish exponentially over time, preventing the network from learning long-term dependencies. Example:
"During the 2020 Tokyo Olympics, the athlete from Kenya won a gold medal in the 10,000-meter race."
In this sentence, understanding that “athlete from Kenya” is associated with “gold medal” requires tracking information across several words. RNNs may struggle to maintain this context due to sequential processing, potentially misrepresenting the relationship.
Long Short-Term Memory networks (LSTMs) are a specialized type of RNN that include memory cells and gating mechanisms to better retain long-term dependencies. While LSTMs alleviate some of the vanishing gradient issues, they still process sequences sequentially, which limits their ability to analyze an entire input simultaneously. Example:
“She set a record in the sprint event.” (Record = Achievement)
“Please hand me the record from the shelf.” (Record = Vinyl Album)
Sequential models often struggle to distinguish context-dependent meanings like these, as they cannot consider the entire sequence in parallel.
How Transformers Solve Context Challenges
Transformers address the limitations of sequential models through their self-attention mechanism, which allows them to evaluate all tokens in a sequence simultaneously. Unlike RNNs and LSTMs, which process data step by step, self-attention enables the model to weigh the importance of each word relative to every other word in the input. This allows the network to capture long-range dependencies and maintain contextual relationships even in complex or lengthy sequences.
In addition to self-attention, Transformers leverage positional encoding to retain information about the order of tokens, since processing is no longer sequential. This combination of parallel processing and positional awareness ensures that the model can understand both the meaning of individual words and their role within the broader context of the sentence. Example:
"The CEO of the company, who recently moved to New York, announced a new innovation hub."
Here, understanding that “who recently moved to New York” refers to “the CEO” requires linking words across the sentence. A Transformer can capture this relationship directly through self-attention, whereas RNNs or LSTMs might struggle as the distance between relevant words increases.
Transformers’ ability to model context at scale also extends beyond natural language processing. They have been successfully applied in computer vision, audio analysis, video understanding, and multimodal tasks, making them a versatile architecture for modern machine learning research and applications. By processing sequences in parallel and maintaining rich contextual representations, Transformers provide a robust solution for tasks that require nuanced understanding of relationships within complex data.
Experimenting with Transformers in Python
Experimenting with Transformers in Python offers a practical pathway to explore how modern attention-based architectures operate, learn, and adapt across real-world tasks. This section walks through a research-focused workflow that includes model loading, fine-tuning, evaluation, and attention analysis, enabling you to move from theoretical understanding to hands-on experimentation with state-of-the-art transformer models.
1. Setting Up the Environment for Transformer Experiments
A reliable environment setup is essential before running any large-scale or research-driven transformer experiments. This stage ensures that all required libraries—such as Transformers, Datasets, PyTorch, and core scientific packages—are available and properly configured. Installing dependencies, verifying library versions, and confirming GPU availability help guarantee consistent, reproducible results during model training and evaluation. Once the environment is initialized, we can seamlessly proceed to loading datasets, tokenizing text, fine-tuning models, and analyzing attention patterns within transformer architectures.
# Step 1: Install required packages
!pip install -q transformers datasets accelerate torch matplotlib seaborn scikit-learn
# Step 2: Imports and version checks
import transformers
print("transformers version:", transformers.__version__)
import torch
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import accuracy_score, f1_score
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Step 3: Check for GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Device:", device)
# Step 4: Load dataset (IMDb for demonstration)
dataset = load_dataset("imdb")2. Preparing the Tokenizer and Model for Downstream Tasks
After setting up the environment and loading the dataset, the next step is to prepare the components that allow transformers to process raw text. This begins with initializing a pretrained tokenizer aligned with the chosen model architecture. The tokenizer breaks text into meaningful subword units while applying padding and truncation to ensure consistent input shapes.
Once the dataset is tokenized, the text column is removed to retain only the numerical representations required for training. With the data prepared, a pretrained transformer model is loaded for sequence classification tasks. Moving the model to the available device—CPU or GPU—ensures efficient computation during fine-tuning and evaluation. This preparation establishes the foundation for running research experiments on transformer behavior, performance, and contextual understanding.
# Step 5: Initialize tokenizer
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Step 6: Tokenize dataset
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)
tokenized_dataset = dataset.map(tokenize, batched=True)
tokenized_dataset = tokenized_dataset.remove_columns(["text"]) # keep only tokenized fields
# Step 7: Load pretrained model
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Move model to GPU if available (Trainer also handles device mapping, but this is explicit)
model.to(device)3. Configuring Fine-Tuning Behavior and Training Strategy
With the tokenizer and model prepared, the next phase focuses on shaping the fine-tuning process to support controlled experimentation. Freezing the first two transformer layers is a common research technique that helps isolate the contributions of deeper layers and reduces computational load. This approach allows the model to retain foundational linguistic patterns while updating only the higher, task-specific layers.
To evaluate performance meaningfully, accuracy and F1-score metrics are defined and integrated into the training loop. These metrics provide clear insight into how well the model distinguishes between sentiment classes during fine-tuning. Training settings are then configured through a set of arguments that control evaluation frequency, checkpoint saving, learning rates, batch sizes, and mixed-precision usage. This structured setup creates a reproducible framework for conducting targeted experiments and analyzing the learning behavior of transformer models.
# Step 8: Freeze the first two transformer layers (partial fine-tuning experiment)
for name, param in model.named_parameters():
if "distilbert.transformer.layer.0" in name or "distilbert.transformer.layer.1" in name:
param.requires_grad = False
# Step 9: Define metrics
def compute_metrics(pred):
labels = pred.label_ids
preds = np.argmax(pred.predictions, axis=1)
return {"accuracy": accuracy_score(labels, preds), "f1": f1_score(labels, preds)}
# Step 10: Training arguments (NOTE: use eval_strategy, not evaluation_strategy)
training_args = TrainingArguments(
output_dir="./custom_results",
eval_strategy="epoch", # <-- correct name is `eval_strategy`
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=1,
weight_decay=0.01,
logging_dir="./custom_logs",
logging_steps=50,
fp16=torch.cuda.is_available(), # use mixed precision if GPU present
)4. Training, Evaluation, and Visualizing Transformer Attention
Once the model, data, and training configuration are prepared, the training pipeline can be executed using the Trainer class. Initializing the Trainer links together the model, datasets, metrics, and training arguments, creating a streamlined workflow for fine-tuning transformer architectures. A subset of the IMDb dataset is selected for faster experimentation, which is especially useful in research scenarios involving multiple trial runs or hyperparameter studies.
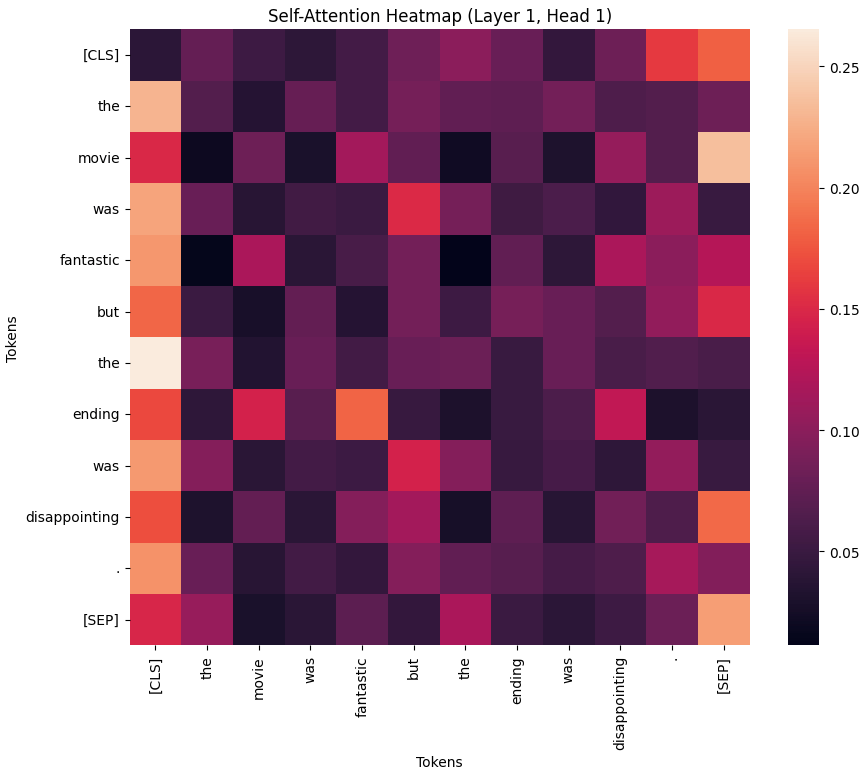
After the training loop completes, the model is evaluated on a held-out test set to measure its performance using accuracy and F1-score. These metrics provide clear insight into how effectively the partially fine-tuned model captures sentiment patterns in text. Finally, an attention visualization is generated to illustrate how the transformer distributes focus across different tokens in a sentence. This heatmap serves as an intuitive way to interpret model behavior, offering a deeper understanding of how self-attention mechanisms capture contextual relationships during inference.
# Step 11: Initialize Trainer (provide eval_dataset because eval_strategy != "no")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"].shuffle(seed=42).select(range(1000)),
eval_dataset=tokenized_dataset["test"].shuffle(seed=42).select(range(500)),
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
# Step 12: Train
trainer.train()
# Step 13: Evaluate
metrics = trainer.evaluate()
print("Evaluation metrics:", metrics)
# Step 14: Attention visualization (example)
inputs = tokenizer("The movie was fantastic but the ending was disappointing.", return_tensors="pt").to(device)
# request attentions via the underlying model
outputs = model.distilbert(**inputs, output_attentions=True)
attentions = outputs.attentions
attention_matrix = attentions[0][0, 0].detach().cpu().numpy() # layer 0, head 0
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0].cpu())
plt.figure(figsize=(10, 8))
sns.heatmap(attention_matrix, xticklabels=tokens, yticklabels=tokens)
plt.title("Self-Attention Heatmap (Layer 1, Head 1)")
plt.xlabel("Tokens")
plt.ylabel("Tokens")
plt.show()Outputs:
Epoch | Training Loss | Validation Loss | Accuracy | F1 |
1 | 0.458500 | 0.348358 | 0.878000 | 0.880626 |
5. Interpreting the Self-Attention Heatmap
The heatmap illustrates how the model distributes attention across tokens in the sentence. Each cell represents the weight assigned by the selected attention head when relating one token to another. Brighter values indicate stronger attention, revealing which words the model considers most informative for understanding contextual relationships. This visualization offers an intuitive perspective into how transformer layers capture meaning, resolve dependencies, and process sentiment within text sequences.
Conclusion
Transformers have reshaped modern machine learning by introducing an architecture capable of capturing long-range dependencies, modeling rich contextual patterns, and scaling efficiently across domains such as text, images, audio, and multimodal data. Through this hands-on exploration in Python, you not only experimented with loading pretrained models and fine-tuning them on real datasets, but also observed how specific components like self-attention operate beneath the surface. Visualizing attention weights, freezing layers for controlled studies, and evaluating performance all contribute to a deeper understanding of how these models learn and generalize.
This practical workflow serves as a foundation for more advanced research, including architecture modification, task-specific adaptation, interpretability studies, and experiments with larger or domain-specialized transformer models. As transformer-based systems continue to evolve, acquiring proficiency in their implementation and behavior equips you with the skills needed to contribute meaningfully to ongoing academic and scientific work in machine learning.



