

Markov Decision Process (MDP): Theory, Mathematics, and Python Implementation
- May 29
- 15 min read
Updated: May 30
Many real-world AI systems must make a sequence of decisions rather than a single prediction. From autonomous vehicles and robotics to recommendation engines and game-playing agents, intelligent systems often operate in environments where actions influence future outcomes. Markov Decision Processes (MDPs) provide a mathematical framework for modeling such decision-making problems and serve as the foundation of reinforcement learning.
This blog introduced Markov Decision Processes (MDPs), a mathematical framework used to model decision-making in environments where outcomes are partly controlled by an agent and partly influenced by uncertainty. We explored the key components of an MDP, including states, actions, rewards, transition probabilities, policies, and value functions, and examined how these elements work together to help an agent determine the best sequence of actions for maximizing long-term rewards.
The blog also covered important concepts such as the Markov property, Bellman equations, policy evaluation, and optimal policy selection. To reinforce the theoretical discussion, a practical Python implementation demonstrated how an MDP can be represented programmatically, how state transitions and rewards can be modeled, and how optimal decisions can be computed. Together, these concepts provide a strong foundation for understanding reinforcement learning and the decision-making mechanisms that power many modern AI systems.

What is a Markov Decision Process (MDP)?
A Markov Decision Process (MDP) is a mathematical framework used to model decision-making problems in environments where outcomes are influenced by both an agent's actions and elements of uncertainty. It provides a structured way to represent situations in which an agent interacts with its environment over time, making a sequence of decisions with the goal of maximizing cumulative rewards.
MDPs are among the most important concepts in reinforcement learning because they provide a formal mathematical model for how an intelligent agent observes its environment, takes actions, transitions between states, and receives feedback. By describing these interactions mathematically, MDPs allow researchers and practitioners to analyze, design, and optimize decision-making algorithms for complex environments.
Consider a robot navigating through a warehouse. At any moment, the robot occupies a specific location, which represents its current state. It can choose actions such as moving forward, turning left, or turning right. Depending on the action taken, the robot transitions to a new state and may receive a reward based on its progress toward a destination. Similar decision-making scenarios arise in self-driving vehicles, recommendation systems, robotics, finance, and game-playing agents.
Few of the core components of an MDP are listed below:
States (S): States represent the various situations in which an agent can exist within an environment.
Actions (A): Actions are the choices available to an agent at any given state.
Transition Probabilities (P): Transition probabilities define the likelihood of moving from one state to another after taking an action.
Reward Function (R): Rewards provide feedback to the agent and indicate the desirability of particular actions or outcomes.
Discount Factor (γ): The discount factor determines the importance of future rewards relative to immediate rewards.
Mathematical Formulation of MDPs
While the components of an MDP provide a conceptual framework for modeling decision-making problems, their true power comes from the mathematical relationships that govern state transitions, rewards, and long-term outcomes. These mathematical foundations enable agents to reason about future consequences and identify actions that maximize cumulative rewards.
At the core of an MDP is the state transition function, which describes how the environment changes when an agent performs an action. The probability of transitioning from a current state (s) to a future state (s') after taking action (a) is represented as:

This transition probability captures the dynamics of the environment and allows us to model both deterministic and stochastic systems.
Another important component is the reward function, which specifies the immediate reward received after taking an action:

In some formulations, the reward may also depend on the resulting state:

The objective of an agent is not simply to maximize immediate rewards but to maximize the total rewards accumulated over time. This concept is represented by the return, which is the sum of future discounted rewards:

1. Gt is the return at time step (t)
2. Rt+1 is the reward received in the next step
3. γ is the discount factor
This formulation allows agents to evaluate the long-term consequences of their decisions rather than focusing solely on immediate outcomes.
Policies in Markov Decision Processes
A policy defines the behavior of an agent by specifying which action should be taken in a given state. In reinforcement learning, the policy effectively represents the agent's strategy for interacting with the environment.
A policy is commonly denoted by:

which represents the probability of selecting action (a) when the agent is in state (s).
The goal of many reinforcement learning algorithms is to discover an optimal policy that maximizes cumulative rewards over time.
1. Deterministic Policies
In a deterministic policy, every state maps to exactly one action. Whenever the agent encounters a particular state, it always chooses the same action.
For example, in a navigation problem:
If the agent is in State A → Move Right
If the agent is in State B → Move Up
Deterministic policies are simple and predictable but may not perform well in highly uncertain environments.
2. Stochastic Policies
In a stochastic policy, actions are selected according to a probability distribution.
For example:
Action | Probability |
Move Left | 20% |
Move Right | 60% |
Move Up | 20% |
Stochastic policies are often useful when exploration is important or when the environment contains uncertainty.
Value Functions for Markov Decision Process (MDPs)
While policies describe what actions an agent should take, value functions measure how beneficial states and actions are in terms of expected future rewards.
Value functions help an agent determine which decisions are likely to produce the greatest long-term return.
1. State Value Function
The state value function estimates the expected cumulative reward obtained by starting from a particular state and following a given policy.
It is represented as:

A higher state value indicates that the state is more desirable because it is expected to lead to greater future rewards.
While the return Gt is the actual accumulated reward from a single sequence of actions, the environment and policy can be stochastic (random). Therefore, an agent cannot know the exact future return from just a single trajectory.
2. Action Value Function
The action value function, often called the Q-function, estimates the expected return of taking a specific action in a given state and then following a policy thereafter.
It is represented as:
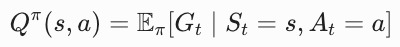
The Q-function evaluates the "quality" of an action. It calculates the expected total discounted reward an agent will receive if it starts in state s, executes action a immediately (even if that action contradicts its current policy), and then strictly follows policy pi for all subsequent steps.
Action value functions form the foundation of many reinforcement learning algorithms, including Q-Learning and Deep Q Networks (DQNs).
Together, state value functions and action value functions enable agents to evaluate alternatives and improve their decision-making strategies.
The Bellman Equation
The Bellman Equation is one of the most important mathematical concepts in reinforcement learning and dynamic programming. Proposed by mathematician Richard Bellman, it provides a recursive relationship for calculating the value of a state.
The key insight behind the Bellman Equation is that the value of a state can be decomposed into two parts:
The immediate reward received.
The value of future states.
This recursive relationship allows complex decision-making problems to be broken down into smaller subproblems.
The Bellman Expectation Equation for a state value function is:

This equation states that the value of a state equals the expected immediate reward plus the discounted value of future states.
The Bellman Optimality Equation shifts the focus from evaluating a policy to finding the best possible policy. The optimal state-value function, denoted as V*(s), represents the maximum expected return achievable from state s by any policy.

These equations form the mathematical foundation of many reinforcement learning algorithms and provide the mechanism through which agents learn optimal behavior.
Solving Markov Decision Processes
The ultimate objective of solving an MDP is to find an optimal policy that maximizes cumulative rewards. Several algorithms have been developed to achieve this objective.
1. Policy Evaluation
Policy Evaluation computes the value function associated with a given policy.
Given a fixed policy, the algorithm repeatedly applies the Bellman Expectation Equation until the state values converge.
The result is an estimate of how good each state is under the current policy.
2. Policy Improvement
Once state values have been estimated, the policy can be improved by selecting actions that lead to higher-value states.
This process updates the agent's behavior and produces a better policy.
3. Policy Iteration
Policy Iteration combines Policy Evaluation and Policy Improvement into a two-step iterative process:
Evaluate the current policy.
Improve the policy using updated value estimates.
These steps are repeated until the policy no longer changes, indicating that an optimal policy has been found.
Policy Iteration is guaranteed to converge to an optimal solution for finite MDPs.
4. Value Iteration
Value Iteration is another popular method for solving MDPs.
Instead of separately evaluating and improving policies, Value Iteration directly updates state values using the Bellman Optimality Equation:

As the values converge, the optimal policy can be extracted by selecting actions that maximize expected future rewards.
Value Iteration is often simpler to implement than Policy Iteration and is widely used in reinforcement learning and planning problems.
Together, these solution methods provide powerful tools for finding optimal strategies in environments modeled by Markov Decision Processes.
Extensions of Markov Decision Process (MDPs)
While Markov Decision Processes provide a powerful framework for modeling sequential decision-making problems, many real-world environments are far more complex than the assumptions made by standard MDPs. In practice, agents may have incomplete information about their surroundings, operate in continuous environments, or interact with other intelligent agents. To address these challenges, researchers have developed several extensions of the traditional MDP framework.
These extensions enable more realistic and scalable modeling of complex decision-making scenarios and form the foundation of many advanced reinforcement learning systems.
1. Partially Observable Markov Decision Processes (POMDPs)
A standard MDP assumes that the agent has complete knowledge of the current state of the environment. However, in many real-world situations, the true state may not be directly observable. For example:
A self-driving car may have limited visibility due to fog or heavy rain.
A robot's sensors may provide noisy or incomplete measurements.
A medical diagnosis system may not have access to all relevant patient information.
Partially Observable Markov Decision Processes (POMDPs) extend MDPs by allowing agents to make decisions based on observations rather than directly observed states. Since the true state is unknown, the agent maintains a belief state, which is a probability distribution over possible states of the environment.
POMDPs are widely used in robotics, autonomous systems, healthcare, and navigation problems where uncertainty and incomplete information are common.
2. Continuous State and Action MDPs
Traditional MDPs often assume that states and actions belong to finite, discrete sets. While this assumption simplifies computation, many real-world systems operate in continuous spaces. Examples include:
The position and velocity of a robot.
The steering angle and acceleration of a vehicle.
Financial portfolio allocation decisions.
Control systems in industrial automation.
In Continuous State and Action MDPs, states and actions can take any value within a continuous range rather than being restricted to predefined categories. These environments are significantly more challenging because the number of possible states and actions can be effectively infinite.
Modern reinforcement learning algorithms such as policy gradient methods, actor-critic models, and deep reinforcement learning techniques are often designed to handle continuous decision spaces.
3. Hierarchical MDPs
As decision-making problems become more complex, solving them directly using a single MDP can become computationally expensive. Hierarchical MDPs address this challenge by decomposing large tasks into smaller, more manageable sub-tasks.
For example, a household robot may have a high-level goal of preparing a meal. This objective can be broken down into smaller tasks such as:
Gathering ingredients.
Preparing cooking utensils.
Cooking the food.
Serving the meal.
Each sub-task can be represented as its own decision-making problem, allowing the agent to solve complex objectives more efficiently.
Hierarchical approaches improve scalability, encourage reusable behaviors, and often accelerate learning in large environments.
4. Multi-Agent Decision Processes
Many environments contain multiple agents that interact with one another rather than a single decision-maker. Examples include:
Autonomous vehicles sharing a road network.
Multiple robots collaborating in a warehouse.
Financial trading systems competing in a market.
Players interacting in multiplayer games.
Multi-Agent Decision Processes extend traditional MDPs by incorporating multiple agents whose actions influence the environment and each other's outcomes.
These systems introduce additional challenges because each agent must consider not only the environment but also the behavior of other agents. Depending on the problem, agents may cooperate, compete, or exhibit a combination of both behaviors.
Multi-agent reinforcement learning has become an active research area with applications in robotics, game theory, distributed systems, and autonomous coordination.
Coding an MDP from Scratch: The Cloud Autoscaler
While standard Reinforcement Learning tutorials rely on abstract grid maps or games like Pong to demonstrate Markov Decision Processes, real-world software engineering leverages MDPs to solve complex operational trade-offs. To bridge the gap between theoretical math and practical programming, we can build a production-ready Cloud Autoscaler environment directly in Python.
Imagine you are a DevOps or Site Reliability Engineer (SRE) managing a cluster of microservices. Your objective is simple: scale your server capacity up or down to keep cloud infrastructure bills minimal, while ensuring you always have enough compute power to prevent catastrophic system outages during unpredictable traffic surges.
We can model this exact infrastructure challenge as an MDP by mapping our system parameters directly to the mathematical core of the framework:
State Space (S): Represented as a combined tuple of (active_servers, traffic_level). Active servers run from 1 to 4, and traffic levels are tracked as 0 (Low), 1 (Medium), or 2 (High).
Action Space (A): At any given decision point, the automation script can choose to HOLD (maintain current count), SCALE_UP (+1 server), or SCALE_DOWN (-1 server).
Transition Probabilities (P): User traffic is stochastic (unpredictable). If current traffic is Medium, there is a 60% chance it stays steady, a 20% chance it cools down to Low, and a 20% chance it spikes to High.
Reward Signal (R): Every active server costs a baseline penalty of -2 to reflect cloud billing. If active servers drop below what the traffic demand requires, the system suffers an outage, triggering a massive penalty of -25. However, if your server count perfectly matches traffic demand, you receive an alignment bonus of +10.
What makes this problem incredibly challenging is that user traffic is non-deterministic. You cannot predict with 100% certainty how many users will access your application in the next ten minutes. However, you do understand historical traffic trends and the operational costs of your infrastructure. This trade-off between resource cost, system safety, and environmental uncertainty is the textbook definition of a control problem.
Python Implementation: The Value Iteration Engine
The script below builds this exact cloud environment and applies the Value Iteration algorithm. It iteratively calculates the expected utility of each infrastructure state, balancing immediate costs against long-term operational risks, until the values converge.
By formulating this architectural dilemma as an MDP, we can use the Value Iteration algorithm to compute a mathematically optimal scaling policy that balances immediate billing constraints against the long-term risk of structural downtime.
Step 1: Initializing the Environment Properties
Every MDP begins by defining the state boundaries, the rules of engagement, and the discount factor (gamma). In this initialization stage, we set up a CloudAutoscalerMDP class to represent our cluster environment.
Our state space (S) tracks pairs of (active_servers, traffic_level). To keep things clean, our infrastructure supports between 1 to 4 active servers, and traffic is classified as 0 (Low), 1 (Medium), or 2 (High). We also explicitly build our stochastic transition matrix inside traffic_transitions. This dictionary defines the environmental probabilities of traffic changes, capturing a realistic, sequential flow where traffic cannot instantly leap from a quiet site to a massive peak without warning.
import numpy as np
class CloudAutoscalerMDP:
def __init__(self):
self.states = [(s, t) for s in range(1, 5) for t
in range(3)]
self.actions = ['HOLD', 'SCALE_UP', 'SCALE_DOWN']
self.gamma = 0.85
self.traffic_transitions = {
0: [0.85, 0.15, 0.00],
1: [0.20, 0.60, 0.20],
2: [0.00, 0.30, 0.70]
}Step 2: Modeling Transitions and Rewards
Now, we need to implement the transition dynamics (P) and reward mechanisms (R). The get_transitions method acts as our core simulation block, mapping out the precise reactions of the system based on the action selected by our automated agent.
First, the function adjusts the server pool according to the incoming action while respecting hard infrastructure bounds (clamping our capacity between 1 and 4). It introduces an administrative action_cost to penalize the system for volatile scaling adjustments.
Next, the function loops through all possible future traffic states based on our transition probabilities.
For every potential outcome, it calculates a tailored reward value. Infrastructure overhead costs a baseline penalty of -2 per server.
If the newly adjusted capacity fails to meet the incoming traffic demand (e.g., 2 servers trying to handle High traffic), the code inflicts a punishing -25 penalty for an SLA outage. If capacity aligns perfectly with user demand, it receives a maximum efficiency bonus of +10.
def get_transitions(self, state, action):
current_servers, current_traffic = state
if action == 'SCALE_UP':
next_servers = min(4, current_servers + 1)
elif action == 'SCALE_DOWN':
next_servers = max(1, current_servers - 1)
else:
next_servers = current_servers
action_cost = -1 if action in ['SCALE_UP', 'SCALE_DOWN']
else 0
transitions = []
for next_traffic, prob in
enumerate(self.traffic_transitions[current_traffic]):
next_state = (next_servers, next_traffic)
server_cost = -2 * next_servers
traffic_demand_map = {0: 1, 1: 2, 2: 4}
required_servers = traffic_demand_map[next_traffic]
if next_servers < required_servers:
performance_reward = -25
elif next_servers == required_servers:
performance_reward = 10
else:
performance_reward = 2
total_reward = action_cost + server_cost +
performance_reward
transitions.append((next_state, prob, total_reward))
return transitionsStep 3: Executing the Value Iteration Loop
With our environment dynamics securely defined, we write the external value_iteration optimization function. This is where the core reinforcement learning math takes over. The algorithm starts by instantiating a blank value table V where every infrastructure state is given an initial value of 0.0. It enters a continuous while True loop that applies the Bellman Optimality Equation. For every single state in our environment, it evaluates the Q-value of each possible action by multiplying the transition probability against the sum of immediate rewards and discounted future values.
The state value table is then updated with the maximum Q-value found. The loop carefully records the largest single value change (delta). Once delta drops below our convergence threshold (epsilon = 0.001), the value table stabilizes, giving us the exact long-term utility score of every cloud state.
def value_iteration(mdp, epsilon=0.001):
V = {s: 0.0 for s in mdp.states}
while True:
delta = 0
new_V = V.copy()
for s in mdp.states:
action_values = []
for a in mdp.actions:
q_val = 0
for next_s, prob, reward in mdp.get_transitions(s, a):
q_val += prob * (reward + mdp.gamma * V[next_s])
action_values.append(q_val)
new_V[s] = max(action_values)
delta = max(delta, abs(new_V[s] - V[s]))
V = new_V
if delta < epsilon:
breakStep 4: Policy Extraction and Driver Execution
Having computed the stabilized utility values for each infrastructure state, the final step is Policy Extraction. Knowing how valuable a state is does not automatically tell our script which command to run; we must perform a one-step lookahead sweep to match those values to actual choices.
The second half of our value_iteration function loops over every state, evaluates the expected returns of our actions using the optimized value table V, and locks in the single action that scores the highest long-term utility.
Finally, our standard Python entry block (if name == "__main__":) runs the entire architecture, loops through the compiled state-action pairs, and outputs a clean, legible console matrix displaying our automated engine's complete policy playbook.
Python
policy = {}
for s in mdp.states:
best_action = None
best_value = float('-inf')
for a in mdp.actions:
q_val = 0
for next_s, prob, reward in mdp.get_transitions(s, a):
q_val += prob * (reward + mdp.gamma * V[next_s])
if q_val > best_value:
best_value = q_val
best_action = a
policy[s] = best_action
return V, policy
if __name__ == "__main__":
scaler = CloudAutoscalerMDP()
values, policy = value_iteration(scaler)
print(f"{'Active Servers':<16} | {'Traffic Level':<15} | {'Optimal Action':<14} | {'State Value':<10}")
print("-" * 65)
traffic_labels = {0: "Low", 1: "Medium", 2: "High"}
for s, t in scaler.states:
print(f"{s:<16} | {traffic_labels[t]:<15} | {policy[(s,t)]:<14} | {values[(s,t)]:6.2f}")Running the Value Iteration engine with a sequential traffic transition matrix yields a highly dynamic control policy. Let's look closely at the compiled matrix output to see exactly how our automated SRE agent resolves infrastructure tradeoffs:
Active Servers | Traffic Level | Optimal Action | State Value
-----------------------------------------------------------------
1 | Low | HOLD | 1.40
1 | Medium | SCALE_UP | -18.52
1 | High | SCALE_UP | -45.16
2 | Low | SCALE_DOWN | 0.40
2 | Medium | HOLD | -17.52
2 | High | SCALE_UP | -35.61
3 | Low | SCALE_DOWN | -3.74
3 | Medium | SCALE_UP | -17.32
3 | High | SCALE_UP | -12.26
4 | Low | SCALE_DOWN | -9.91
4 | Medium | HOLD | -16.32
4 | High | HOLD | -11.26The most prominent pattern in this matrix is how the agent behaves when traffic is Low. Regardless of how over-provisioned the cluster gets, the policy systematically scales down to match the quiet environment:
At 4 servers - SCALE_DOWN to 3
At 3 servers - SCALE_DOWN to 2
At 2 servers - SCALE_DOWN to 1
At 1 server - HOLD (our baseline infrastructure floor)
Because the traffic transition rules state that a quiet site cannot instantly flash-surge to peak demand (P = 0.0 from Low to High), the algorithm recognizes that stepping down is safe. It is mathematically guaranteed a warning window traffic must hit Medium first giving the controller ample time to react and scale back up before an outage occurs.
Look at the cluster's decision when it sits at 3 Active Servers during Medium Traffic:
3 | Medium | SCALE_UP | -17.32In this state, 3 servers are technically more than enough to sustain Medium demand, which only requires 2. A simple threshold-based reactive rule would sit idle or downscale to save money.
However, the MDP calculates the long-term expected value of future transitions. It knows that Medium traffic carries a 20% risk of escalating to High. If a surge hits while the cluster only has 3 servers, it triggers the heavy SLA violation penalty (-25). To eliminate this vulnerability, the policy proactively issues a SCALE_UP command to secure the 4-server ceiling before the peak demand manifests.
You will notice that almost all the calculated State Values (the long-term expected cumulative utility) are negative numbers. This is completely normal for optimization problems focused on cost mitigation.
Because our reward function heavily penalizes continuous cloud infrastructure costs (-2 per server) and system downtime, the negative values represent the inevitable baseline cost of keeping an application online. The closer a value is to zero, the more optimized the state is.
Notice that the absolute highest value in the entire matrix is 1.40 at (1 Server, Low Traffic). This is the system’s "sweet spot," where infrastructure expenditures are perfectly minimized without violating user demand constraints.
Conclusion
Markov Decision Processes provide one of the most important foundations for understanding how intelligent agents make decisions in uncertain environments. By representing problems in terms of states, actions, rewards, and transitions, MDPs offer a structured approach to evaluating choices and identifying strategies that maximize long-term outcomes. Their ability to model sequential decision-making has made them a cornerstone of reinforcement learning and many real-world optimization problems.
As AI applications continue to expand across robotics, autonomous systems, finance, healthcare, and recommendation engines, the principles of Markov Decision Processes remain highly relevant. A solid understanding of MDPs not only helps in solving current decision-making problems but also provides the groundwork for exploring advanced reinforcement learning algorithms and developing more sophisticated autonomous agents in the future.



