

Machine Learning in Python Made Easy: Regression, Clustering & Q-Learning Explained
- Apr 19, 2024
- 7 min read
Updated: Feb 4
Machine learning can be simple — when explained with real, runnable Python examples. In this blog, we’ll walk through key machine learning techniques, from supervised learning like regression, to unsupervised learning like clustering, and even reinforcement learning with Q-learning on the FrozenLake environment. With step-by-step code and clear explanations, this hands-on guide is perfect for anyone looking to learn ML through Python.

Introduction to Machine Learning with Python
Machine learning (ML) is a core component of modern data science and artificial intelligence, enabling systems to learn from data and improve performance without being explicitly programmed. ML algorithms generally fall into three major categories:
Supervised Learning – where models learn from labeled data (e.g., regression, classification).
Unsupervised Learning – where patterns are discovered in unlabeled data (e.g., clustering, dimensionality reduction).
Reinforcement Learning – where agents learn to make decisions through trial and error (e.g., Q-learning).
In this tutorial, we’ll explore these three types of machine learning with easy-to-follow Python implementations. You’ll learn how to build models using real code for regression, clustering, and reinforcement learning (via OpenAI Gym's FrozenLake). Whether you're new to ML or brushing up your skills, this hands-on guide will help you understand the core concepts through practical examples.
Few Machine Learning Algorithms with Examples in Python:
Machine learning techniques can be broadly categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, algorithms learn from labeled data, where each input is associated with the correct output. It's like teaching a child with answer keys; the algorithm learns patterns and relationships to make predictions on new, unseen data. Unsupervised learning, on the other hand, doesn't rely on labeled data; instead, it identifies hidden patterns or structures within the data. It's akin to organizing a messy room without labels; the algorithm groups similar items together or reduces the clutter to reveal underlying insights. Lastly, reinforcement learning is all about learning by trial and error, where an agent interacts with an environment, taking actions and receiving feedback in the form of rewards or penalties. It's like teaching a dog tricks; the agent learns through positive or negative reinforcement to achieve a desired outcome. Each type of machine learning technique has its unique approach and applications, offering versatile tools for solving diverse problems.Machine learning can be broadly classified into three categories:
1. Supervised Learning
Supervised learning stands at the forefront of cutting-edge advancements in artificial intelligence, harnessing the power of labeled data to drive innovation across diverse domains. At its pinnacle, supervised learning algorithms, fueled by sophisticated neural network architectures and deep learning techniques, exhibit unprecedented capabilities in understanding complex patterns and making accurate predictions. Leveraging massive datasets and computational resources, state-of-the-art models such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformer architectures have revolutionized fields like computer vision, natural language processing, and speech recognition. With the relentless pursuit of pushing the boundaries of performance and scalability, supervised learning continues to spearhead breakthroughs in AI research, paving the way for transformative applications that redefine human-computer interaction and shape the future of technology.
Supervised Machine Learning using Python - Linear Regression
Below is a simple example of supervised machine learning using Python's scikit-learn library. We'll use a linear regression model over a randam synthetic housing data with two features.
Importing Libraries
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_errornumpy: used for numerical operations and handling arrays.
train_test_split: splits data into training and test sets.
LinearRegression: the regression model.
mean_squared_error: evaluates model performance.
Creating the Dataset
X = np.array([[1, 800], [2, 1000], [2, 1200], [3, 1500], [3, 1700], [4, 2000]])
y = np.array([50000, 60000, 75000, 90000, 100000, 120000])X contains features: [number of bedrooms, size of the house in sq ft].
y contains target variable: house price.
Splitting Data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)test_size=0.2: 20% of data is used for testing.
random_state=1: ensures reproducibility of results.
Creating and Training the Model
model = LinearRegression()
model.fit(X_train, y_train)Making Predictions
y_pred = model.predict(X_test)Evaluating the Model
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
Output:
Mean Squared Error: 6267313.019390583In this example, we generate synthetic housing data with two features: the number of bedrooms and the size of the house (in square feet). We then split the data into training and test sets, create a linear regression model, train it on the training data, and make predictions on the test data. Finally, we evaluate the model's performance using the mean squared error metric.
2. Unsupervised Learning
Unsupervised learning represents the cutting edge of machine learning, pushing the boundaries of AI innovation by unlocking the latent potential within vast troves of unlabelled data. This advanced approach transcends traditional paradigms, enabling algorithms to autonomously discover intricate patterns, structures, and relationships without the need for explicit supervision. Unsupervised learning ventures into uncharted territory, unraveling the complexities of raw data to unveil hidden insights and drive transformative breakthroughs across diverse domains. In this era of unprecedented data abundance, unsupervised learning stands as a beacon of ingenuity, paving the way for novel discoveries, disruptive innovations, and unparalleled advancements in artificial intelligence.
Un-Supervised Machine Learning using Python - K-Means Clustering
Here's a simple Python code example using the K-means clustering algorithm, one of the most widely used unsupervised machine learning algorithms:
Import Libraries and Generate Data
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# Generate synthetic data with 4 clusters
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)We create 300 synthetic data points grouped into 4 clusters with some spread using make_blobs.
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Synthetic Data')
plt.show()Output:

Fit K-Means and Get Predictions
# Create and fit KMeans model
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
# Get labels and cluster centers
labels = kmeans.labels_
centers = kmeans.cluster_centers_We create a KMeans object with 4 clusters, fit it to the data, and retrieve both the predicted labels and the cluster centers.
Visualize Clusters and Centroids
# Plot data points colored by cluster label
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
# Plot cluster centers
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('K-means Clustering')
plt.show()Output:
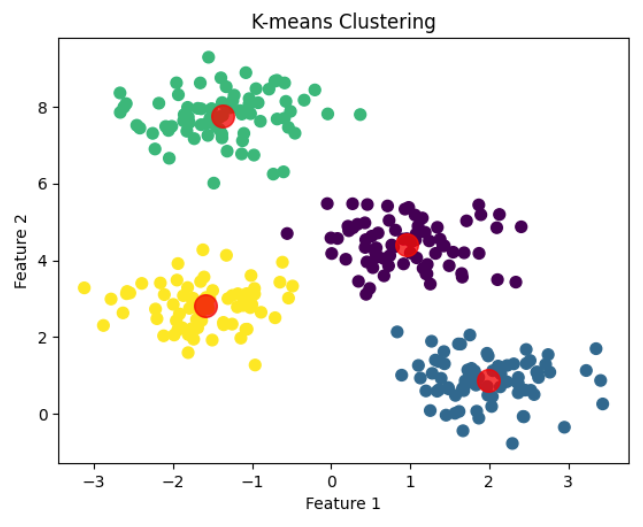
This visualization highlights the discovered clusters and shows the red centroids representing the center of each cluster.
Above code demonstrates the following simple steps:
Generating synthetic data.
Visualizing the synthetic data.
Creating and fitting a K-means clustering model using KMeans Algorithm.
Obtaining the cluster centers and labels from the trained model.
Visualizing the clusters and centroids.
3. Reinforcement Learning
In the forefront of artificial intelligence, Reinforcement Learning (RL) stands as a beacon of cutting-edge innovation. At its most advanced, RL embodies the essence of autonomous decision-making, where intelligent agents navigate complex environments to achieve goals through trial, error, and continual learning. This paradigm leverages sophisticated algorithms, such as deep reinforcement learning (DRL), which combine deep neural networks with reinforcement learning principles to master tasks ranging from video game strategy to robotic control. Advancements in RL are pushing the boundaries of what's possible, enabling agents to excel in domains previously deemed inaccessible to machines.
Reinforcement Machine Learning using Python - FrozenLake Q-learning
If you're diving into reinforcement learning with Python, one of the best beginner-friendly environments to experiment with is FrozenLake from OpenAI Gym. In this tutorial, we’ll walk through how to implement the classic Q-learning algorithm to train an agent that learns to navigate a slippery frozen lake without falling into holes. By updating a Q-table based on trial-and-error experiences, the agent gradually improves its strategy to reach the goal safely. This hands-on example is a great way to understand core RL concepts like state-action pairs, reward maximization, and the explore-exploit trade-off, all within a simple yet powerful 4x4 gridworld. We’ll also include detailed print statements throughout the training and evaluation process to help you visualize the learning in action.
import gym
import numpy as np
# Initialize environment and Q-table
env = gym.make("FrozenLake-v1", is_slippery=True)
Q = np.zeros((env.observation_space.n, env.action_space.n))
print("Initialized Q-table with shape:", Q.shape)
# Hyperparameters
lr = 0.8
gamma = 0.95
episodes = 1000
epsilon = 0.1
print(f"Starting Q-learning training for {episodes} episodes...\n")
# Training
for ep in range(1, episodes + 1):
state = env.reset()
done = False
step = 0
total_reward = 0
while not done:
# Epsilon-greedy action selection
if np.random.rand() < epsilon:
action = env.action_space.sample()
action_type = "Explore"
else:
action = np.argmax(Q[state])
action_type = "Exploit"
next_state, reward, done, _ = env.step(action)
old_value = Q[state, action]
next_max = np.max(Q[next_state])
# Q-learning update
Q[state, action] = (1 - lr) * old_value + lr * (reward + gamma * next_max)
print(f"Episode {ep} | Step {step} | State: {state} | Action: {action} ({action_type}) | "
f"Reward: {reward} | Next State: {next_state} | Done: {done}")
print(f" Q[{state}, {action}] updated from {old_value:.4f} to {Q[state, action]:.4f}")
state = next_state
total_reward += reward
step += 1
if ep % 100 == 0:
print(f"--> Episode {ep} completed. Total reward this episode: {total_reward}\n")
print("\nTraining completed.\n")
# Evaluation
eval_episodes = 100
total_eval_reward = 0
print(f"Evaluating agent over {eval_episodes} episodes using greedy policy...\n")
for ep in range(1, eval_episodes + 1):
state = env.reset()
done = False
ep_reward = 0
step = 0
while not done:
action = np.argmax(Q[state])
next_state, reward, done, _ = env.step(action)
print(f"[Eval {ep}] Step {step} | State: {state} | Action: {action} | "
f"Reward: {reward} | Next: {next_state} | Done: {done}")
ep_reward += reward
state = next_state
step += 1
print(f"--> Eval Episode {ep} ended with reward: {ep_reward}\n")
total_eval_reward += ep_reward
avg_reward = total_eval_reward / eval_episodes
print(f"✅ Average reward after evaluation: {avg_reward:.2f}")
env.close()
Output:
[Eval 97] Step 24 | State: 8 | Action: 0 | Reward: 0.0 | Next: 12 | Done: True
--> Eval Episode 97 ended with reward: 0.0
[Eval 100] Step 16 | State: 4 | Action: 0 | Reward: 0.0 | Next: 0 | Done: False
[Eval 100] Step 17 | State: 0 | Action: 0 | Reward: 0.0 | Next: 4 | Done: False
[Eval 100] Step 18 | State: 4 | Action: 0 | Reward: 0.0 | Next: 8 | Done: False
[Eval 100] Step 19 | State: 8 | Action: 0 | Reward: 0.0 | Next: 12 | Done: True
--> Eval Episode 100 ended with reward: 0.0
✅ Average reward after evaluation: 0.00This code uses a Q-table to learn the optimal policy for navigating the Frozen Lake environment. It iteratively updates the Q-values based on rewards obtained from actions taken in each state. Finally, the trained agent is evaluated by running it through the environment multiple times and calculating the average reward.
In conclusion, machine learning is a vast and dynamic field — but getting started doesn’t have to be overwhelming. In this tutorial, we explored the three core types of machine learning: supervised learning, unsupervised learning, and reinforcement learning — all demonstrated through practical, Python-based examples.
From building regression models to clustering unlabeled data, and training an agent to navigate a frozen lake using Q-learning in OpenAI Gym, you’ve learned how fundamental machine learning concepts translate into real, runnable code. These examples not only build your theoretical understanding but also develop the practical skills needed to implement and improve machine learning models on your own.



