

What is the Vanishing Gradient Problem?
- May 6
- 7 min read
Deep learning has become the backbone of modern artificial intelligence, enabling breakthroughs in areas like natural language processing, computer vision, and speech recognition. At the core of these advancements are deep neural networks, which learn by adjusting their internal parameters through a process called backpropagation.
As these networks grow deeper, training them becomes increasingly complex. One of the most critical challenges that arises is the vanishing gradient problem, where gradients shrink as they propagate backward through the network. This results in minimal updates to the earlier layers, preventing the model from learning effectively.
This blog explores the vanishing gradient problem in deep neural networks, explaining why it occurs, how it affects model learning, and the techniques used to overcome it, along with a practical implementation to visualize its impact.

Understanding the Vanishing Gradient Problem
The vanishing gradient problem is a common issue encountered when training deep neural networks using backpropagation. It occurs when gradients, which are used to update the model’s weights, become extremely small as they propagate backward through multiple layers.
In a neural network, learning happens by adjusting weights based on the gradient of the loss function. During back-propagation, these gradients are passed from the output layer back to the earlier layers. However, in deep architectures, this process involves repeated multiplication of small derivative values.
As a result, the gradients shrink exponentially as they move toward the initial layers. This leads to negligible weight updates in those layers, effectively preventing them from learning meaningful features.
Over time, this imbalance causes the network to rely heavily on the later layers while the earlier ones remain undertrained. This not only slows down convergence but also limits the overall performance of the model, especially in tasks that require learning hierarchical representations.
Why Gradients Vanish in Deep Neural Networks
The vanishing gradient problem primarily arises from how gradients are computed during backpropagation in deep neural networks. As gradients flow backward from the output layer to earlier layers, they are calculated using the chain rule of derivatives, which links together gradients across multiple layers.

In deep networks, this means the gradient is essentially a product of many small terms. When these derivatives are less than 1, repeated multiplication causes the gradient to decrease exponentially as it moves toward earlier layers.
To understand this intuitively, consider a simplified case where each derivative is around 0.5. After several layers, the gradient shrinks rapidly:
( 0.5 ) ^ n
As the number of layers increases, this value approaches zero, leaving earlier layers with almost no learning signal.
Activation functions further amplify this issue. For example, the sigmoid function compresses inputs into a narrow range between 0 and 1, producing very small gradients for large positive or negative inputs.
σ′ ( x ) = σ ( x ) ( 1 − σ ( x ) )
Since the derivative of the sigmoid function is always less than or equal to 0.25, stacking multiple layers compounds the shrinking effect.
As a result, gradients reaching the initial layers become negligibly small, preventing meaningful weight updates. This causes early layers to learn extremely slowly or stop learning entirely, limiting the model’s ability to capture foundational patterns in the data.
Impact of the Vanishing Gradient Problem
The vanishing gradient problem has a significant impact on the training and performance of deep neural networks. While the issue originates from mathematical properties of backpropagation, its consequences are very practical and often severe.
One of the most immediate effects is slow or stalled learning in early layers. As gradients diminish during backpropagation, the initial layers receive extremely small updates
Another major consequence is poor feature extraction. In deep neural networks, lower layers are responsible for capturing fundamental patterns such as edges, textures, or simple structures. If these layers fail to learn effectively, the entire network suffers because higher layers depend on these basic features.
The problem also leads to longer training times and inefficient convergence. Since only the later layers continue to learn, the model struggles to optimize the loss function, often getting stuck in suboptimal states.
In sequential models like recurrent neural networks, the impact becomes even more pronounced. The vanishing gradient problem makes it extremely difficult for the model to learn long-term dependencies, as information from earlier time steps effectively fades away during training.
Overall, the vanishing gradient problem limits the depth and effectiveness of neural networks, making it a critical challenge that has shaped the development of modern deep learning techniques.
Overcoming the Vanishing Gradient Problem
The vanishing gradient problem was a major roadblock in training deep neural networks, but several techniques have been developed to address it effectively. Modern deep learning architectures rely on a combination of these strategies to ensure stable and efficient training.
One of the most widely used solutions is the ReLU (Rectified Linear Unit) activation function. Unlike sigmoid or tanh, ReLU does not squash values into a small range. For positive inputs, its derivative remains constant:
f′ ( x ) = 1 for x > 0
This helps maintain stronger gradients during backpropagation, reducing the risk of them vanishing across layers.
Another important technique is proper weight initialization. Methods like Xavier and He initialization are designed to keep the variance of activations consistent across layers. This prevents gradients from shrinking or growing uncontrollably as they propagate through the network.
Batch normalization is also widely used to stabilize training. By normalizing the inputs of each layer, it reduces internal covariate shift and helps maintain a steady flow of gradients throughout the network.
A major breakthrough came with residual connections, introduced in deep residual networks (ResNets). These connections allow gradients to bypass certain layers by creating shortcut paths, making it easier for the network to propagate learning signals backward without significant loss.
For sequence-based models, specialized architectures like LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Units) were developed. These models use gating mechanisms to preserve information over longer sequences, effectively addressing the vanishing gradient issue in recurrent neural networks.
In practice, overcoming the vanishing gradient problem often involves combining multiple techniques. Together, they enable the training of very deep networks that power modern applications in artificial intelligence.
Python Implementation: Visualizing the Vanishing Gradient Problem
To better understand how gradients vanish in deep neural networks, a simple experiment can be performed using PyTorch. Instead of relying only on theory, this implementation demonstrates how gradient values behave across multiple layers during backpropagation.
A deep neural network is constructed with multiple fully connected layers, using both sigmoid and ReLU activation functions for comparison. The sigmoid activation is known to contribute to vanishing gradients, while ReLU helps preserve gradient flow in deeper architectures.
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
# Config
depth = 50
input_size = 10
hidden_size = 10
class DeepNet(nn.Module):
def __init__(self, activation):
super().__init__()
layers = []
for _ in range(depth):
layers.append(nn.Linear(hidden_size, hidden_size))
layers.append(activation())
self.net = nn.Sequential(
nn.Linear(input_size, hidden_size),
*layers,
nn.Linear(hidden_size, 1)
)
def forward(self, x):
return self.net(x)During the backward pass, gradients are computed for each layer based on the loss function. The magnitude of these gradients is then recorded across all layers to observe how they change as they propagate backward through the network.
def get_gradients(model):
x = torch.randn(1, input_size)
y = torch.randn(1, 1)
loss_fn = nn.MSELoss()
output = model(x)
loss = loss_fn(output, y)
loss.backward()
grads = []
for param in model.parameters():
if param.grad is not None:
grads.append(param.grad.abs().mean().item())
return grads
# Models
sigmoid_model = DeepNet(nn.Sigmoid)
relu_model = DeepNet(nn.ReLU)
sigmoid_grads = get_gradients(sigmoid_model)
relu_grads = get_gradients(relu_model)
layers = np.arange(len(sigmoid_grads))To make the behavior more interpretable, multiple visualizations are incorporated into the analysis. A gradient flow plot illustrates how gradient magnitudes vary across different layers of the network, providing a clear view of how information propagates during backpropagation. In addition, a log-scale plot is used to highlight the exponential decay of gradients, making the vanishing effect far more visible than on a standard linear scale. A distribution histogram further complements this by showing how gradient values are concentrated, particularly near zero in networks using sigmoid activation.
# ---- Plot 1: Gradient Flow ----
plt.figure()
plt.plot(layers, sigmoid_grads, marker='o', label='Sigmoid')
plt.plot(layers, relu_grads, marker='x', label='ReLU')
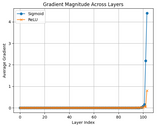
plt.title("Gradient Magnitude Across Layers")
plt.xlabel("Layer Index")
plt.ylabel("Average Gradient")
plt.legend()
plt.grid()
plt.show()
# ---- Plot 2: Log Scale (Critical Insight) ----
plt.figure()
plt.plot(layers, np.log10(sigmoid_grads), marker='o', label='Sigmoid (log scale)')
plt.plot(layers, np.log10(relu_grads), marker='x', label='ReLU (log scale)')
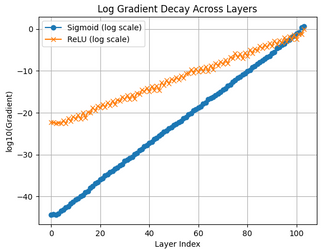
plt.title("Log Gradient Decay Across Layers")
plt.xlabel("Layer Index")
plt.ylabel("log10(Gradient)")
plt.legend()
plt.grid()
plt.show()
# ---- Plot 3: Gradient Distribution ----
plt.figure()
plt.hist(sigmoid_grads, bins=20, alpha=0.5, label='Sigmoid')
plt.hist(relu_grads, bins=20, alpha=0.5, label='ReLU')
plt.title("Distribution of Gradient Magnitudes")
plt.xlabel("Gradient Value")
plt.ylabel("Frequency")
plt.legend()
plt.show()The results clearly demonstrate that in networks with sigmoid activation, gradients shrink rapidly as the depth of the network increases. This leads to extremely small updates in the earlier layers, effectively limiting their ability to learn. In contrast, networks using ReLU activation maintain relatively stable gradient values, allowing learning to persist across deeper layers.




The visualizations provide a clear and practical view of how gradients behave across layers in deep neural networks, highlighting the contrast between sigmoid and ReLU activations.
1. The log-scale gradient decay plot reveals the most important insight. Gradients corresponding to sigmoid activation show a steep downward trend as the layer index decreases, indicating exponential decay. This confirms that gradients quickly become negligible in earlier layers. In contrast, the ReLU curve declines much more gradually, demonstrating a more stable gradient flow even in deeper networks.
2. The distribution histogram of gradient magnitudes further reinforces this observation. In the case of sigmoid activation, most gradient values are heavily concentrated near zero, indicating that a large portion of the network receives almost no learning signal. ReLU, on the other hand, shows a wider spread of gradient values, suggesting healthier propagation of information during backpropagation.
3. The standard gradient flow plot (linear scale) appears less dramatic but still provides useful context. While both activations may seem similar at first glance, this view hides the severity of gradient decay due to scale compression. The sharp spike near the final layers reflects where gradients are still strong, while earlier layers remain close to zero, especially in the sigmoid case.
Together, these visualizations demonstrate that networks using sigmoid activation experience significant gradient decay as depth increases, leading to severe vanishing gradients in earlier layers. In contrast, ReLU maintains comparatively stronger gradients, enabling more effective learning throughout the network.
This implementation provides a clear, practical illustration of the vanishing gradient problem. It reinforces the underlying theory and emphasizes the importance of activation function choice in ensuring stable and efficient training of deep neural networks.
Conclusion
The vanishing gradient problem remains one of the most fundamental challenges in training deep neural networks. As gradients propagate backward through multiple layers, their tendency to shrink exponentially can severely limit the ability of earlier layers to learn meaningful representations. This not only slows down training but also impacts the overall performance of the model.
Through both theoretical explanation and practical visualization, it becomes clear that the issue is deeply rooted in the mechanics of backpropagation and the choice of activation functions. While traditional functions like sigmoid contribute to gradient decay, modern approaches such as ReLU, improved weight initialization, normalization techniques, and residual connections have significantly reduced its impact.
Understanding the vanishing gradient problem is essential for designing effective deep learning models. With the right architectural choices and training strategies, it is possible to build deep networks that learn efficiently and perform reliably across a wide range of real-world applications.



